
Memory Allocator for OpenMP Programs
[Report] [Presentation] [Code]
Summary
A Research Project aimed at implementing a scalable and concurrent memory allocator for parallel applications (OpenMP), utilizing the concepts of per-thread heaps with memory ownership that can scale efficiently while almost eliminating false sharing and minimizing fragmentation. This project was developed and implemented as part of the Multicore Processors: Architecture & Programming Course during my Graduate Study.
Abstract
The end of Moore’s Law necessitates the development of innovative solutions to augment the performance of applications rather than attempting to pack more transistors on a chip and/or increasing the CPU frequency. In this direction, Multicore and Multiprocessor systems are now ubiquitous and are an ideal candidate to improve performance as they enable the execution of parallel, multithreaded programs. However, these parallel applications are often inhibited by the memory allocator which can negatively throttle performance and scalability. Moreover, the memory allocator can also introduce other issues such as false sharing and fragmentation which can be considerable bottlenecks to performance. This project presents a scalable memory allocator that can be used in conjunction with these parallel applications (even those developed with OpenMP). It introduces the concept of per thread heaps with memory ownership that can scale efficiently while almost eliminating false sharing and minimizing fragmentation. The generated results for the developed OpenMP benchmark programs denote substantial promise with the proposed and implemented memory allocator exhibiting considerable improvements in Scalability, False Sharing avoidance, and low Fragmentation as compared to the Malloc and Hoard memory allocators.
Implementation Details
- As part of the research, experimentation and development of the Scalable Memory Allocator for OpenMP Programs, 3 different incremental versions of the Memory Allocator were developed and experimented with as follows:
- Sequential Memory Allocator: This was the very first version of the Memory Allocator developed which supported only single-threaded client programs. The main objective of this allocator was to develop and finalize some of the core ideas and features inherent to the Memory Allocator such as Book Keeping Node, Free List Node, Alignment to word and page boundaries, Search through Best Fit algorithm, Split and Merge operations, Map and Unmap system calls.
- Concurrent Memory Allocator (Serial Single Heap): The previous version of the memory allocator was such that it was completely sequential and could only support single threaded client applications. The objective of this version of the allocator was to augment the previous version to support multithreaded client applications while maintaining the core features. This was done through the introduction of a mutex to lock and unlock access to the data structures and operations of the single heap under consideration.
- Concurrent and Scalable Memory Allocator (Per Thread Heap): Although the previous version of the memory allocator supports multithreaded applications, it serializes the memory operations due to the controlled access to the single shared heap. The objective of this incremental version of the memory allocator was to work around this and better support concurrent, scalable and parallel memory allocation. This was done by maintaining a heap per thread with memory ownership rather than a single global heap as in the previous version.
Results
- In order to compare the different memory allocators, namely Malloc, Hoard and My_mem_alloc (corresponds to the Concurrent and Scalable Memory Allocator developed as part of this project), various benchmark programs were developed as below:
- Speed: In order to compare the different memory allocators for speed, single threaded and multithreaded benchmark programs were developed under different categories, namely, No Malloc or Free, CPU bound and Memory bound. Execution Time was used as the metric for comparison. The generated results are summarized in the graphs below:
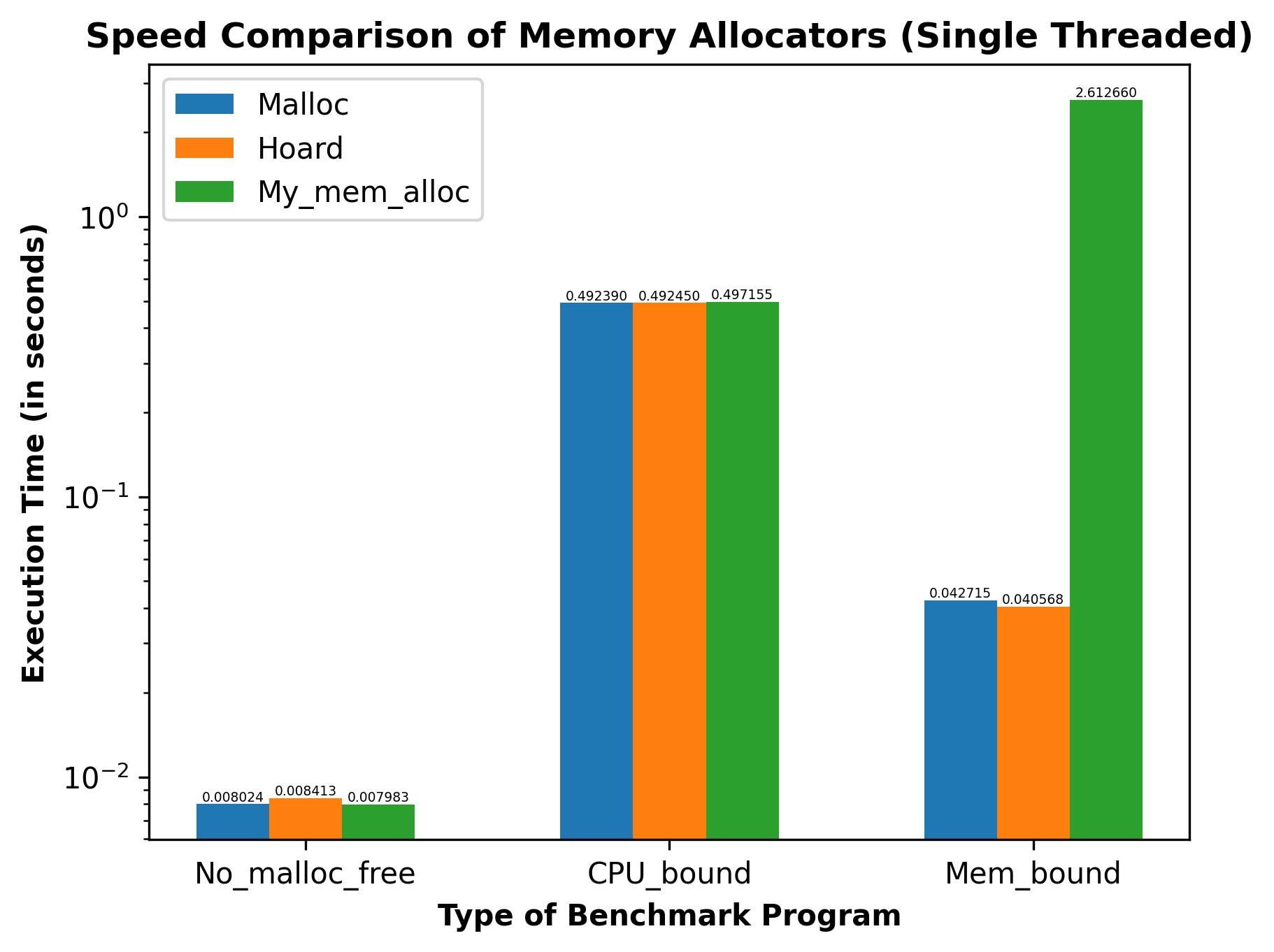
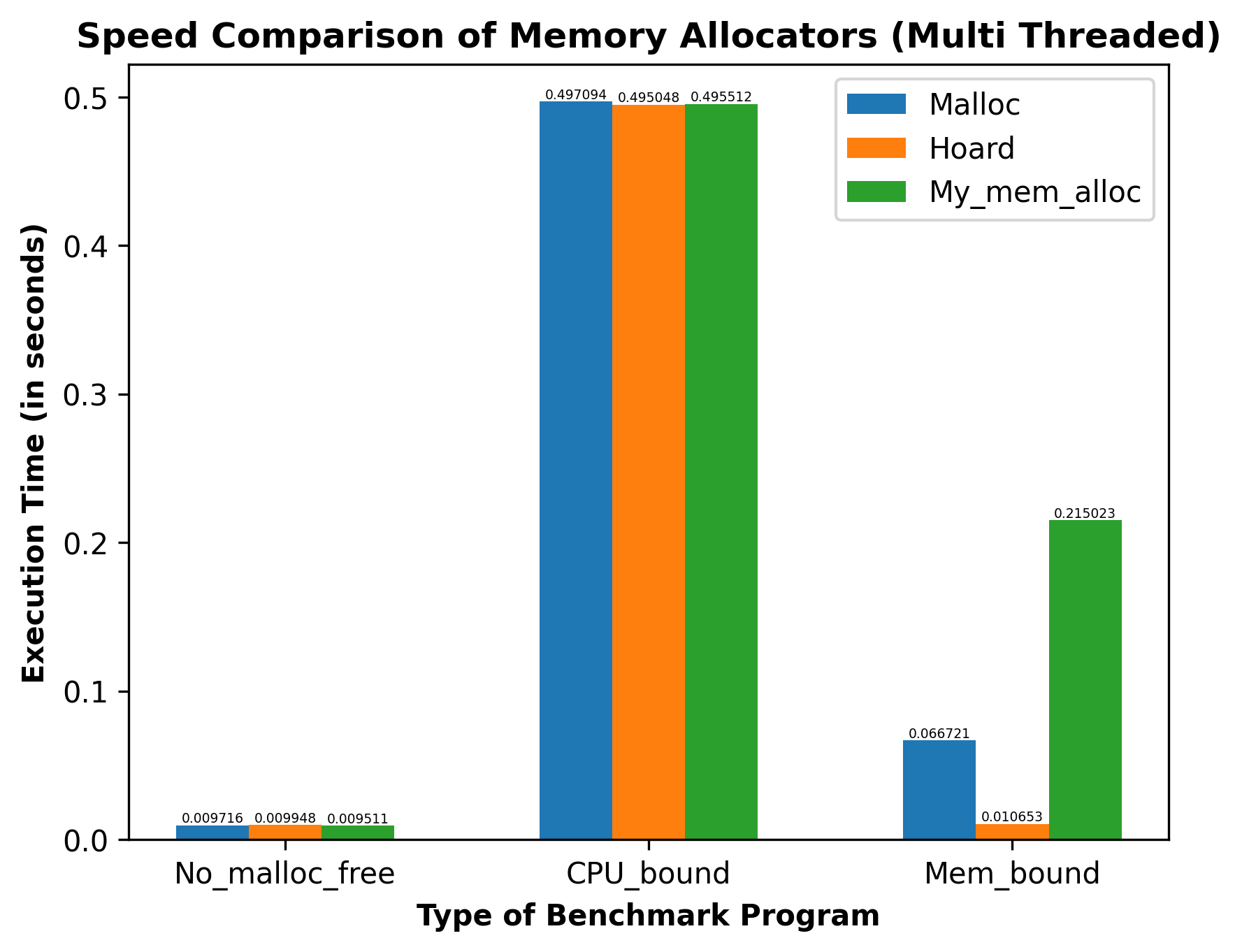
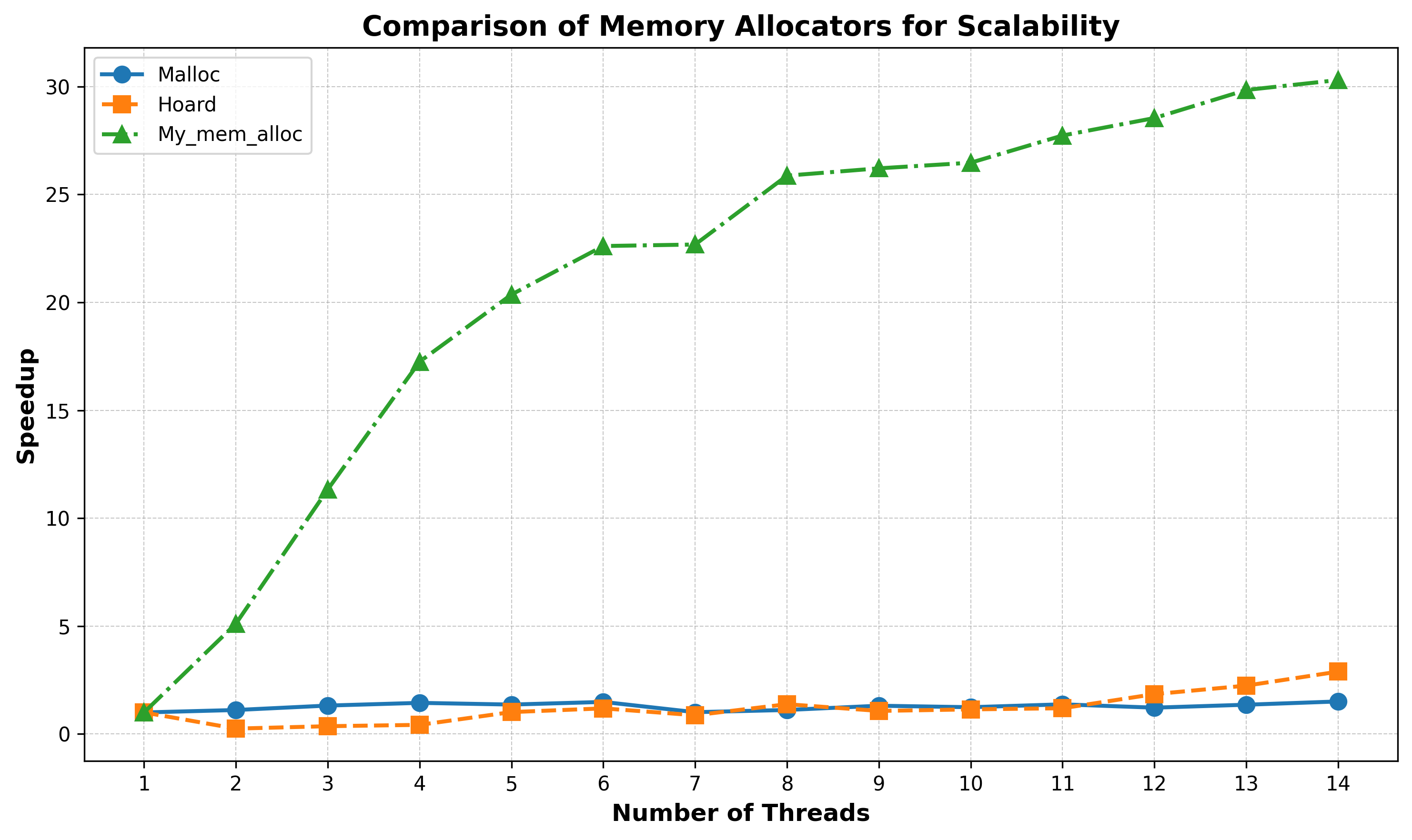
- Scalability: A benchmark was developed to compare the memory allocators for scalability. Speedup was used as the metric for comparison. The generated results are summarized in the graph below:
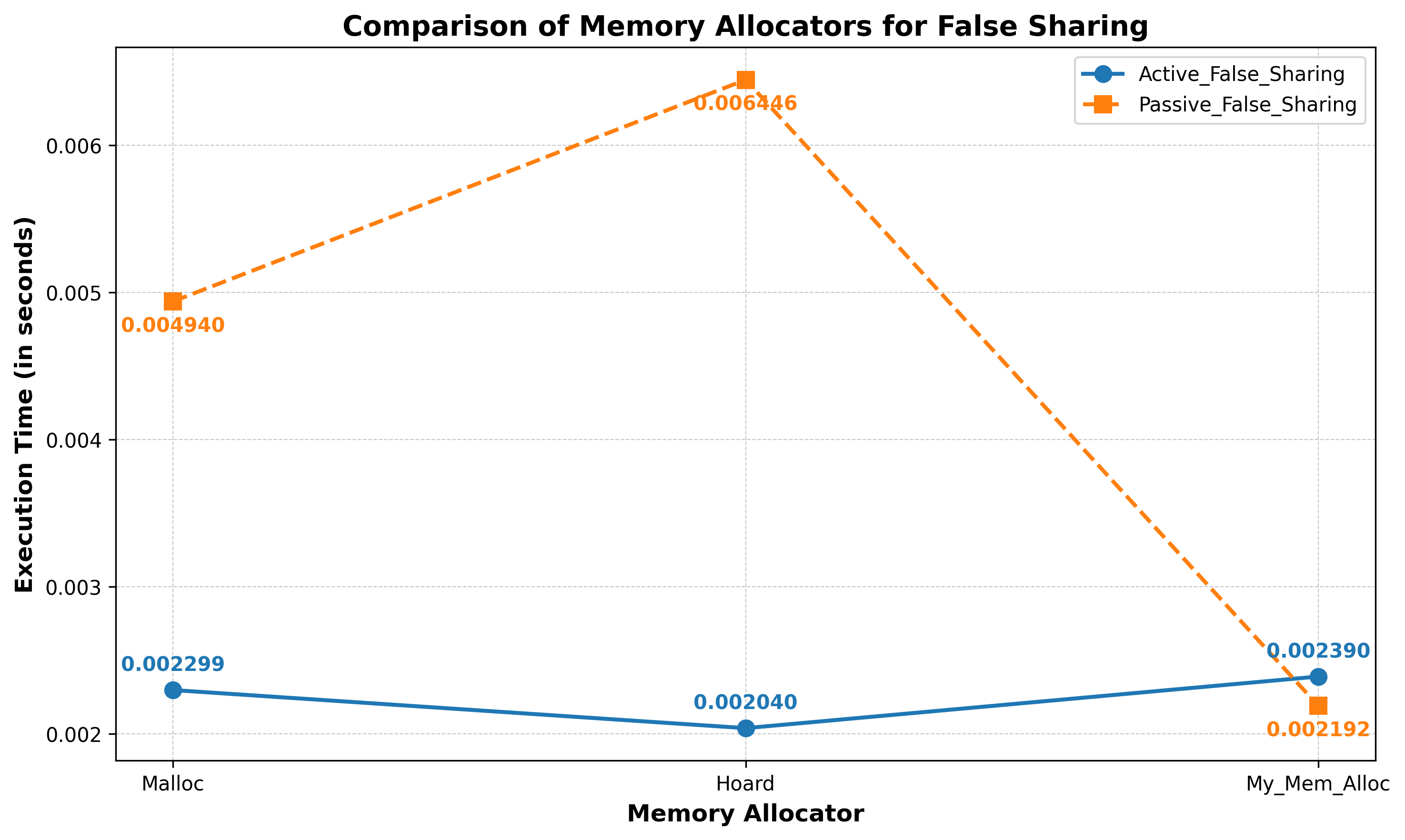
- False Sharing Avoidance: With regards to False Sharing, two categories of benchmarks were developed, namely, Active False Sharing and Passive False Sharing. Execution Time was used as the metric for comparison. The generated results are summarized in the graph below:
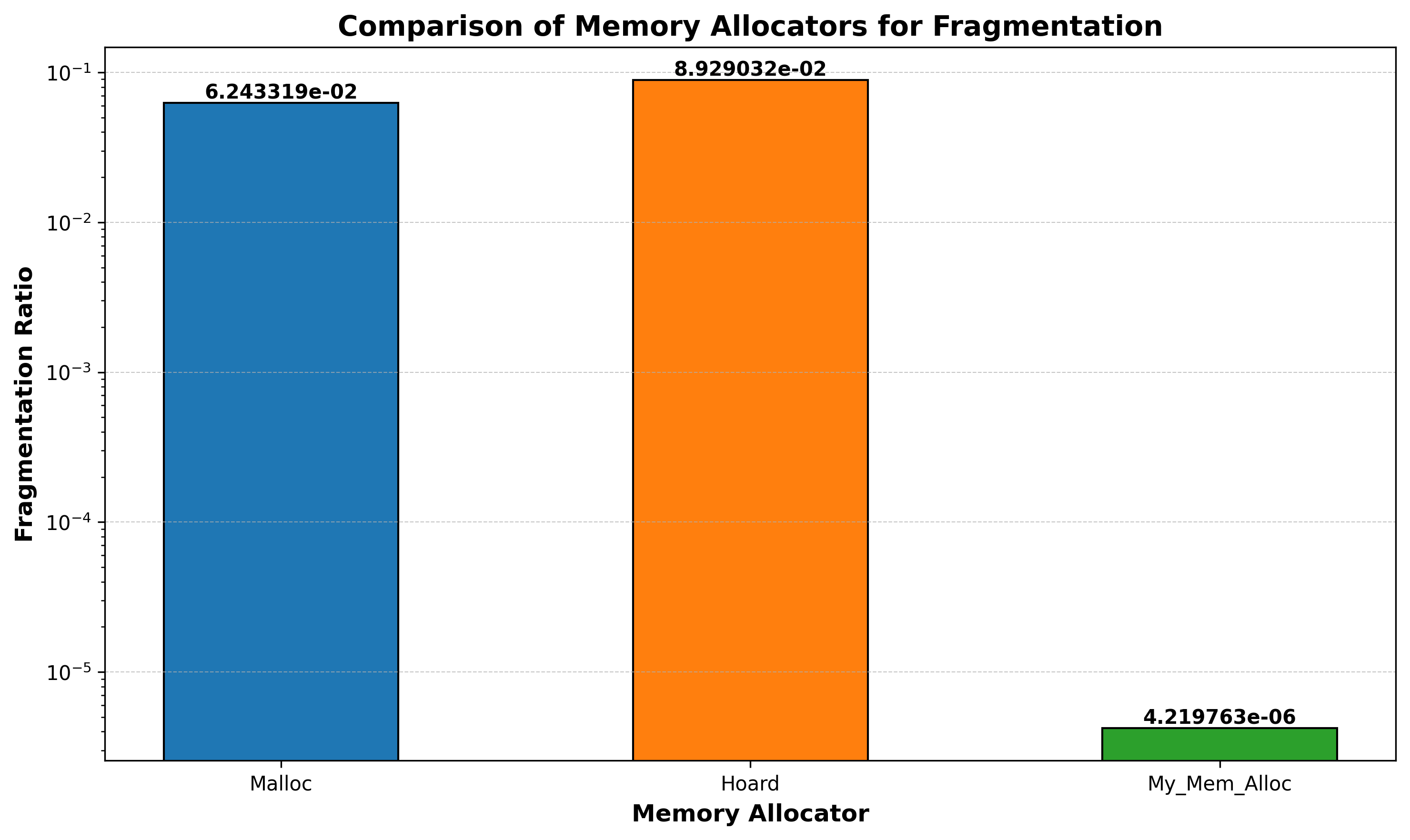
- Fragmentation: A benchmark was developed to compare the memory allocators for Fragmentation. Fragmentation Ratio (Max amount of memory allocated from OS / Max amount of memory required by application) was used as the metric for comparison. The generated results are summarized in the graph below:
- Speed: In order to compare the different memory allocators for speed, single threaded and multithreaded benchmark programs were developed under different categories, namely, No Malloc or Free, CPU bound and Memory bound. Execution Time was used as the metric for comparison. The generated results are summarized in the graphs below: